Сглаживание экспоненциальным методом
Сервис позволит провести сглаживание временного ряда yt экспоненциальным методом, т.е. простроить модель Брауна (см. пример).
Инструкция. Укажите количество данных (количество строк), нажмите Далее. Полученное решение сохраняется в файле Word.
St = (1-α)yt + αSt-1St = αyt + (1-α)St-1В практических задачах обработки экономических временных рядов рекомендуется (необоснованно) выбирать величину параметра сглаживания в интервале от 0.1 до 0.3. Других точных рекомендаций для выбора оптимальной величины параметра α пока нет. В отдельных случаях предлагается определять величину α исходя их длины сглаживаемого ряда: α = 2/(n+1).
Что касается начального параметра S0, то в задачах его берут или равным значению первого уровня ряда у1, или равным средней арифметической нескольких первых членов ряда. Если при подходе к правому концу временного ряда сглаженные этим методом значения при выбранном параметре α начинают значительно отличаться от соответствующих значений исходного ряда, необходимо перейти на другой параметр сглаживания. Достоинством этого метода является то, что при сглаживании не теряются ни начальные, ни конечные уровни сглаживаемого временного ряда.
Сглаживание экспоненциальным методом в Excel
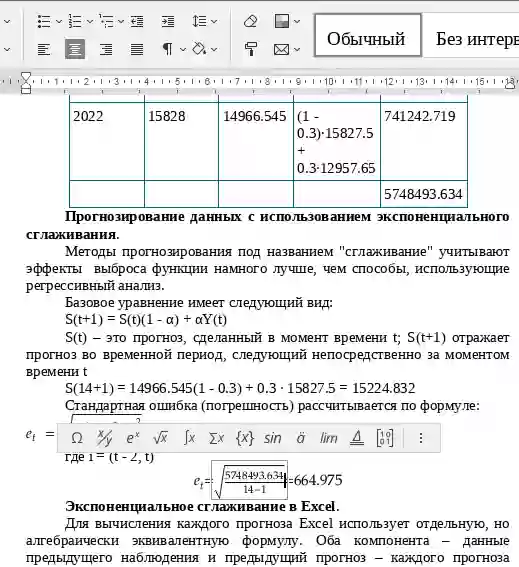
Для вычисления каждого прогноза MS Excel использует отдельную, но алгебраически эквивалентную формулу. Оба компонента – данные предыдущего наблюдения и предыдущий прогноз – каждого прогноза умножаются на коэффициент, отображающий вклад данного компонента в текущий прогноз.Активизировать средство Экспоненциальное сглаживание можно, выбрав команду Сервис/Анализ данных после загрузки надстройки Пакет анализа (подробнее).
Пример. Проверить ряд на наличие выбросов методом Ирвина, сгладить методом экспоненциального сглаживания (α = 0.1).
В качестве S0 берем среднее арифметическое первых 3 значения ряда.
S0 = (50 + 56 + 46)/3 = 50.67
| t | y | St | Формула |
| 1 | 50 | 50.07 | (1 - 0.1)*50 + 0.1*50.67 |
| 2 | 56 | 55.41 | (1 - 0.1)*56 + 0.1*50.07 |
| 3 | 46 | 46.94 | (1 - 0.1)*46 + 0.1*55.41 |
| 4 | 48 | 47.89 | (1 - 0.1)*48 + 0.1*46.94 |
| 5 | 49 | 48.89 | (1 - 0.1)*49 + 0.1*47.89 |
| 6 | 46 | 46.29 | (1 - 0.1)*46 + 0.1*48.89 |
| 7 | 48 | 47.83 | (1 - 0.1)*48 + 0.1*46.29 |
| 8 | 47 | 47.08 | (1 - 0.1)*47 + 0.1*47.83 |
| 9 | 47 | 47.01 | (1 - 0.1)*47 + 0.1*47.08 |
| 10 | 49 | 48.8 | (1 - 0.1)*49 + 0.1*47.01 |